1.避免锁
1.1 预分配,外部不允许修改内部状态等
2.避免IO
3.异步化
4.数据落地尽可能批量化
另外,从应用建模时候尽可能让数据维护本身自己,而非外部系统修改(可以天然的并行化,而不需要考虑锁),具体来说DDD,ACTOR等等都是这种思想.
在一个理想状态下,不考虑跨语言的情况下,每个对象只能由自身维护其数据的情况下,那么扩展性能够达到最大,因为完全避免的锁
1.避免锁
1.1 预分配,外部不允许修改内部状态等
2.避免IO
3.异步化
4.数据落地尽可能批量化
另外,从应用建模时候尽可能让数据维护本身自己,而非外部系统修改(可以天然的并行化,而不需要考虑锁),具体来说DDD,ACTOR等等都是这种思想.
在一个理想状态下,不考虑跨语言的情况下,每个对象只能由自身维护其数据的情况下,那么扩展性能够达到最大,因为完全避免的锁
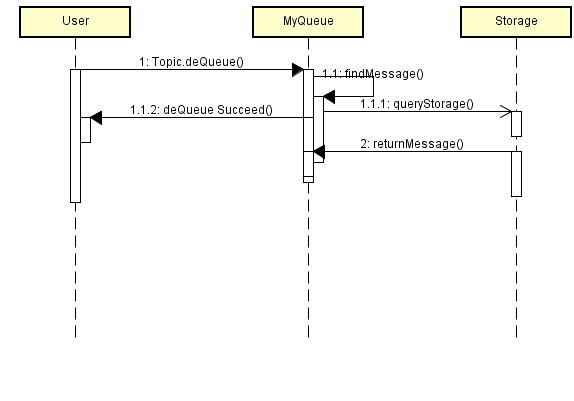
消息入队:

消息出队:
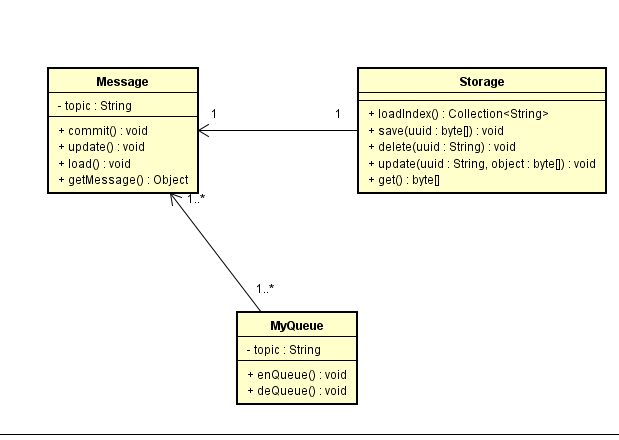
完全依赖Storage作为拓展点,若是单机消息队列,则直接实现单机Storage
若是集群存储则实现集群Storage
若是分布式存储则实现分布式的Storage
所有上层操作依赖Storage接口
分别是CompressFileStorage, SplitFileStorage
分别实现场景是,单消息单文件存储
多消息单文件存储
Github地址:
https://github.com/michaelssss/MyQueue
1.确定领域界限(通常由领域专家和架构师共同确定)
2.抽象领域的套路,就是通过和领域专家交流,确定出在当前领域下的各种套路
Example:
以软件发布作为一个领域来陈述:
首先确定,当前业务界限(已开发完毕,通过测试,需要在某个商城或者平台上架)
接下来,涉及,当前商店的适配(Adapter),提交审核(Commit,Audit),最后是上架(sell granted/publish)
以上作为最基本的讨论术语。而这些专业名词,也就是俗称的套路。
3.通过动态验证模型是否满足需求,否则转2。
不断的重复交流并验证,最终得出一个模型。(类似于软件开发中的迭代,这里是模型的迭代,而非软件的迭代,但模型的迭代能够深层次的影响软件的迭代)
只要模型抽象的足够好,面向对象中的SOLID原则会自然而然的呈现,而非刻意而为。
从一个比赛题目来看业务设计应该如何设计
先说,数据库设计如下
![D:\msg\602254985\Image\Group\Image2\D]6[ZU2KJ27UP8WFNDFZR8L.png](https://michaelssss.com/wp-content/uploads/2017/08/d-msg-602254985-image-group-image2-d6zu2kj27up8-1-1.png)
题目:
要求设计一个接口getBlogList(userid,int begin,int offset)
返回blog以下数据
{
“Blog”:[
“blogid”:xxx, //博客id
“createtime”:xxx, //博客创建时间,需最新的在最前羰
“readflag”:1/0, //当前用户的已读状态
“praiselist”:[“xxx”,”yyyy”,”zzz”,……], //当前博客的点赞人例表
“commentlist”:[“xxx”,”yyy”,”zzz”,……] //当前博客的评论人例表
]
“Blog”:[
“blogid”:xxx,
“createtime”:xxx,
“readflag”:1/0,
“praiselist”:[“xxx”,”yyyy”,”zzz”,……],
“commentlist”:[“xxx”,”yyy”,”zzz”,……]
]
……
}
模拟数据数量级为百万级别
让我们来看看再不考虑内存占用下的最优解:
所有表预存至本地内存
提前对所有数据做好计算,到时候单纯的根据bloguid就可以在N(1)的时间下拿到数据和对象
十条数据
耗时1ms
输出压缩json大小23KB

两百条数据
耗时16ms
输出压缩json大小485KB

接下来把点赞详情和阅读详情操作给去除
十条数据:
耗时低于ms级别
输出json压缩大小低于kb级别

两百条数据:
耗时2ms
输出压缩json大小11KB

接下来把点赞数和阅读数加入操作中
十条数据:
耗时1ms
输出压缩json大小低于KB数量级

两百条数据
耗时10ms
输出压缩json大小17KB

问题在于,现实系统中,博文数量及点赞数一般的比这些模拟数据要大得多,且不可能完全load进内存中.
在上面的最优解中,瓶颈在于输出的数据量,也就是网络IO瓶颈
单次map是内存操作,一般是ns级别
网络通信的的时间一般是ms级别
彼此相差三个数量级,那么可以猜想,无论如何优化系统的响应时间也应该与这次测试相差三个数量级甚至更多.
那么以上题目放在实际系统场景中问题是什么呢?
针对以上,从业务上应该做如下规避:
DbC的核心思想是对软件系统中的元素之间相互合作以及“责任”与“义务”的比喻。这种比喻从商业活动中“客户”与“供应商”达成“契约”而得来。例如:
供应商必须提供某种产品(责任),并且他有权期望客户已经付款(权利)。
客户必须付款(责任),并且有权得到产品(权利)。
契约双方必须履行那些对所有契约都有效的责任,如法律和规定等。
同样的,如果在面向对象程序设计中一个类的函数提供了某种功能,那么它要:
期望所有调用它的客户模块都保证一定的进入条件:这就是函数的先验条件—客户的义务和供应商的权利,这样它就不用去处理不满足先验条件的情况。
保证退出时给出特定的属性:这就是函数的后验条件—供应商的义务,显然也是客户的权利。
在进入时假定,并在退出时保持一些特定的属性:不变式。
契约就是这些权利和义务的正式形式。我们可以用“三个问题”来总结DbC,并且作为设计者要经常问:
它期望的是什么?
它要保证的是什么?
它要保持的是什么?
很多编程语言都有对这种断言的支持。然而DbC认为这些契约对于软件的正确性至关重要,它们应当是设计过程的一部分。实际上,DbC提倡首先写断言。
契约的概念扩展到了方法/过程的级别。对于一个方法的契约通常包含下面这些信息:
可接受和不可接受的值或类型,以及它们的含义
返回的值或类型,以及它们的含义
可能出现的错误以及异常情况的值和类型,以及它们的含义
副作用
先验条件
后验条件
不变式
(不太常见)性能上的保证,如所用的时间和空间
继承中的子类型可以弱化先验条件(但不可以加强它们),并且可以加强后验条件和不变式(但不能弱化它们)。这些原则很接近Liskov代换原则。
所有类之间的关系就是客户与供应商的关系。一个客户在调用供应商的功能时有义务不去违反供应商所需的状态。相应的,供应商也有义务为客户提供它所需的状态和数据。例如,供应商的delete功能要求客户在data buffer当中有数据存在。相应的,供应商要保证当delete功能完成后,data buffer中的数据已被删除。其它的设计契约还有不变式。不变式保证类的状态在任何功能被执行后都保持在一个可接受的状态。
当使用契约时,供应商不应对契约条件是否被满足进行校验。大体的思想是,利用契约条件校验为保护网,在契约被违反的情况下代码要“死翘翘”(fail hard)。DbC的“死翘翘”概念让对契约行为的调试变简单,因为每个过程的行为意图被定义得很清楚。它和一种叫作defensive programming的方法明显不同,在那种方法里,供应商要负责解决先验条件不满足的情况。相对通常的情况下,在DbC和defensive programming中,如果客户违反了先验条件供应商都会抛出异常—由客户来负责解决这种情况。DbC让供应商的工作更简单。
DbC同时也定义了软件模块的正确性条件:
如果对一个供应商的调用之前类的不变式和先验条件是真,那么在调用后不变式和后验条件也为真。
当调用供应商时,软件模块应保证不违反供应商的先验条件。
因为契约条件在程序运行中不应被违反,它们可以只作为调试代码,或者在发布版本中被移除从而得到更好的性能。
DbC也能帮助代码重用,因为每段代码的契约都被很好的文档化了。模块的契约可以被当做软件文档来 描述模块的行为。
——————-from Wikipedia
为啥要抄这个呢,因为我司比较蠢…接口的字段都是变化的…..
函数(数学意义上)关注映射
面向对象编程则是尽可能的将变化封装.
两者都是为了降低开发人员的脑力负担,简化应用模型.
没有说哪个更好.需要根据具体场景来完成技术选型.
意味着几件事情。
第一,参与这个系统的角色一定有多个,若只有一个角色,且只有一个动作,那就退化成面向过程编程。
第二,需要规约出系统的各个角色,以及相互之间的交互
第三,根据需要抽象出各种抽象层。
第四,每个抽象层的实现就是面向过程编程
note1.其实所谓的组件化就是合理的抽象出系统内的角色,然后以服务的形式对外运行,而非原来的代码层面的内联。
note2.现有大部分编程事件都是面向过程的层次,很少涉及设计,也少有人员想要先去设计
产品提出需求->产品经理及项目经理评估需求->开发测试产品确定,细化需求,给出需求用例->测试给出测试用例->开发测试共同给出技术方案->开发->迭代测试->上线
需求必须留档,且产品需给出User Case角度的用例
其中用例可用于系统的自动化
测试用例是以黑箱角度给出,且应为产品的UserCase的细化
用例必须留档,提出bug必须依据用例,并生成bug用例进行验证
每次迭代只应该做增量测试,每天自动化做全量测试
用例Example:
测试:
动作:用户激活账号
前置条件:用户账号已注册且保持未激活状态
执行接口/事件:*.do 点击xxxx按钮,激活如下事件
预期:接口返回/事件结束/抛出异常/etc
产品:
测试:
动作:用户激活账号
前置条件:用户账号已注册且保持未激活状态
预期:用户成功激活账号
另外,开发和测试其实应该要求是一样的,都应该懂代码,完全的黑箱非自动化的测试是会搞死人的
1、继承并实现IntentService
2、在Main里面start自己的Service
3、注意防杀措施
REST是实现SOA的一种技术手段
比如服务与服务之间的通信采用REST接口。
但其实服务与服务之间通信不仅是可以REST,同时可以用消息队列,分发器,soap等等
更具体的是,SOA代表一种战略意图,REST是实现战略意图的一种战术