对照着需求文档我们对平台进行建模
首先第一点关注到的是关键词
- 应用
- 授权
- 审核
- 开发者
- 企业
所以创建以下几个对象:
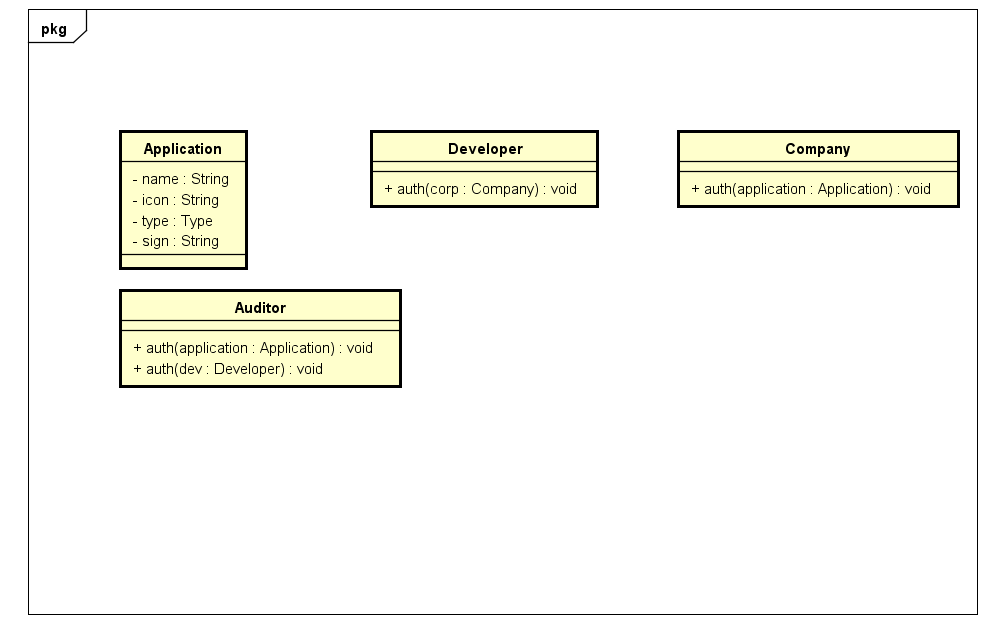
关注到授权是个动作,我们将auth的动作添加到几个对象上去,注意到几个auth的对象不一样,我们需要做区分,按传参区分
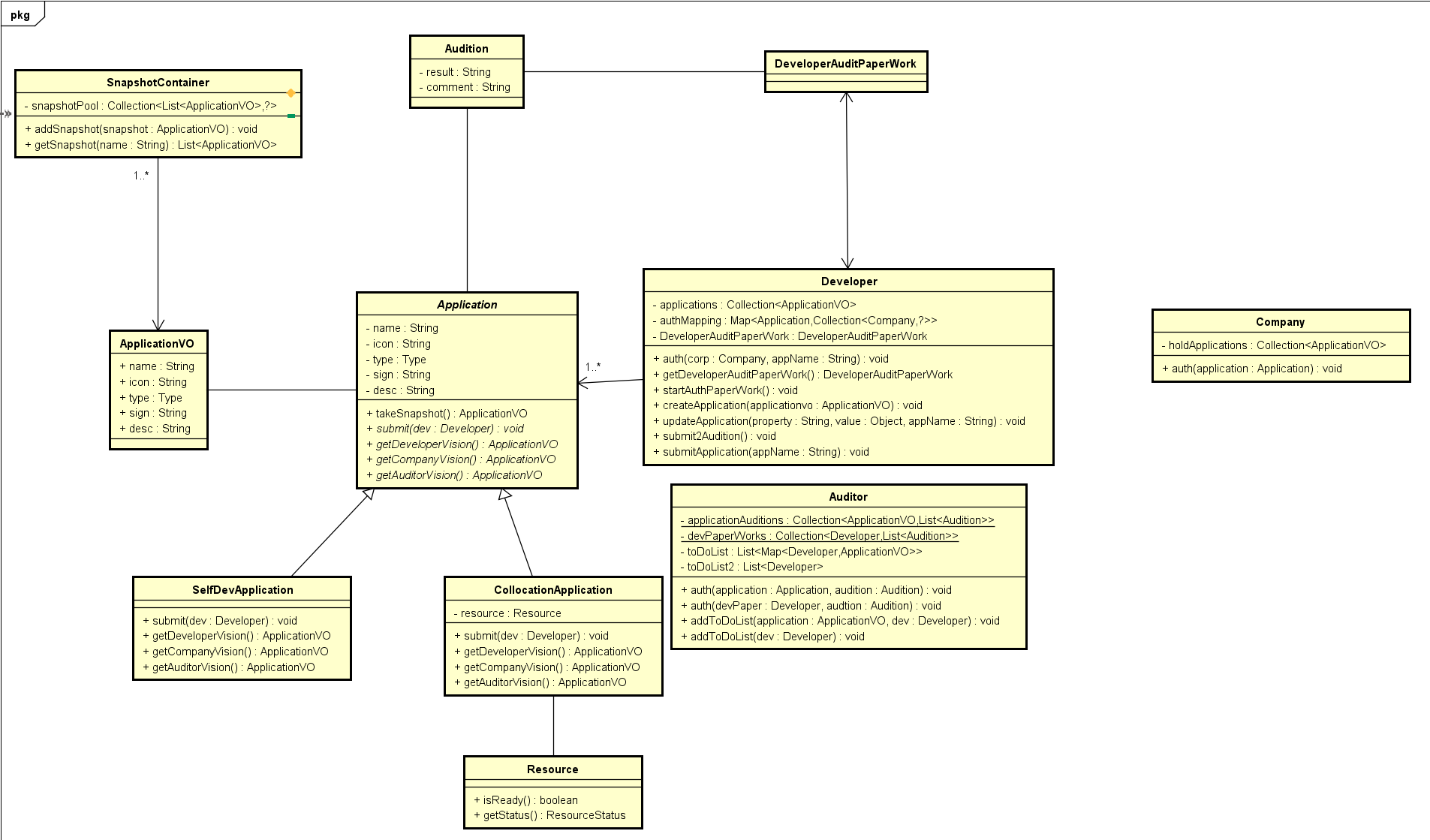
此时我们动态的再脑中运行一下,发现这个模型只满足了授权的需要,我们把其他需求添加进来
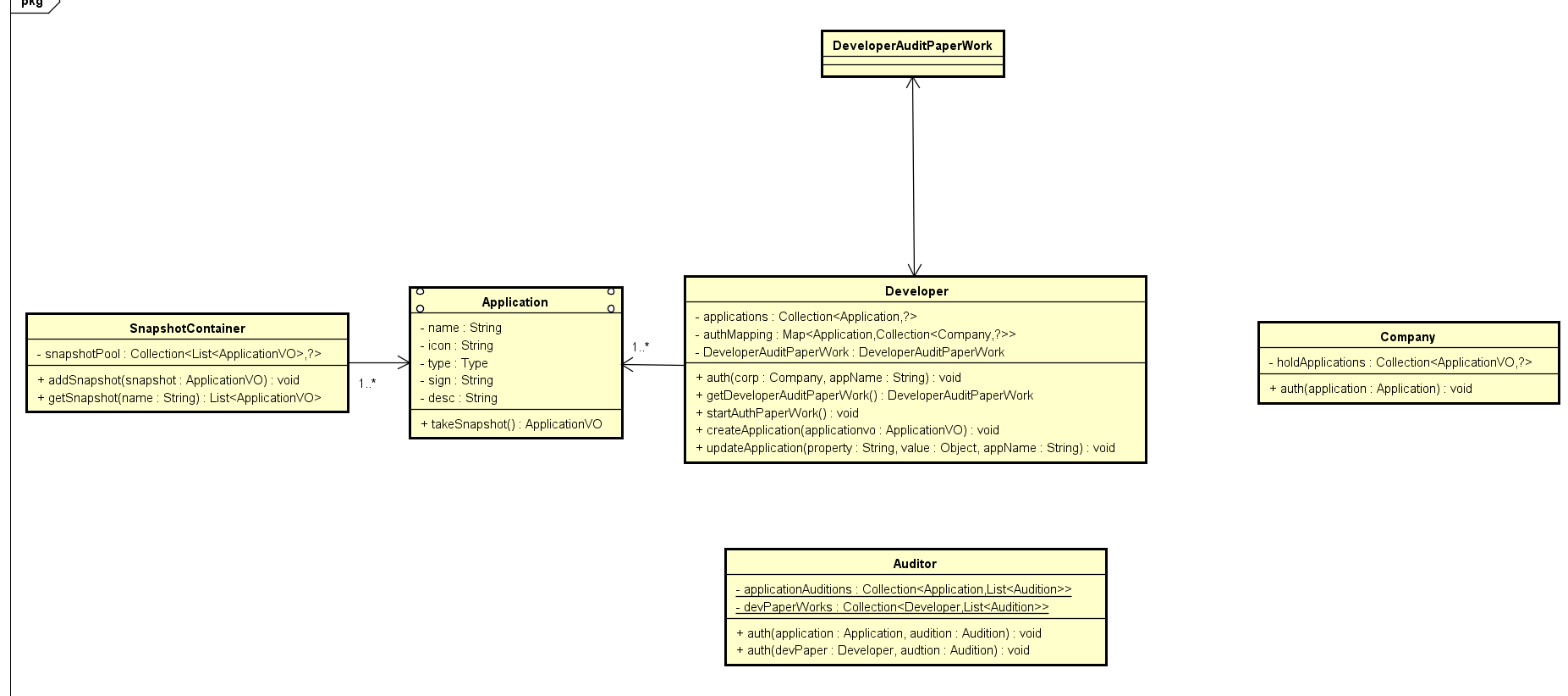
现在就差Application的状态跃迁由谁来负责了
按照逻辑上来讲,开发者应该知道应用开发的整个生命流程,但是由于这是在第三方平台上,有一些不可见的逻辑,我们这时候应该把Application的状态职责由Application自己负责管理所以如下:
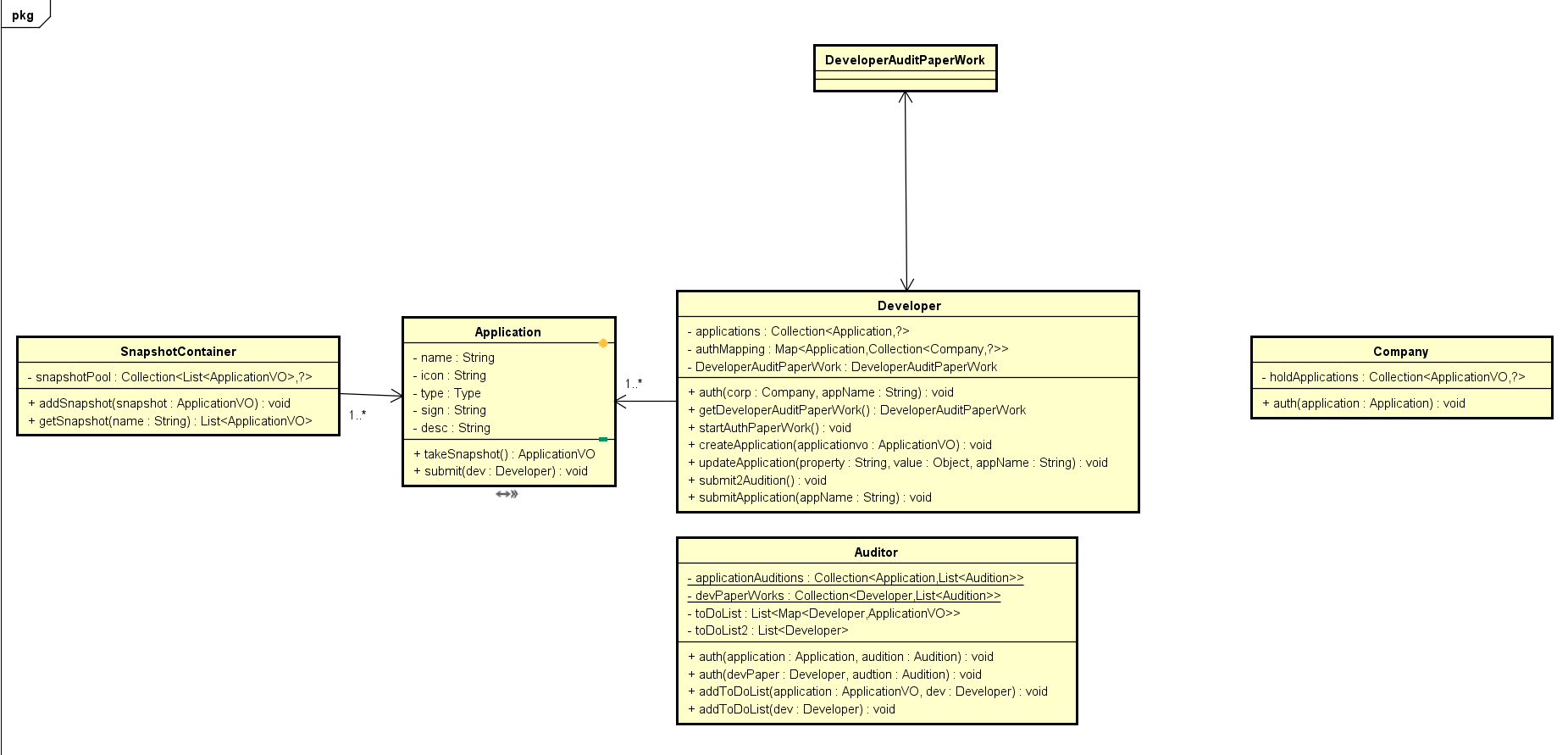
这个时候发现,Developer和Application都自己负责了自己的生命周期的进行,所有操作只是发起了一个流程。
另外,关注到,审核的信息其实是Application的一个Snapshot而已,所以无论外界对Snapshot做了什么都不会影响到Application本身,但是要注意到,Snapshot本来不应该可以被修改,故而要有final修饰。
这时候核心的几个概念就已经可以用这个类图来表达了。
接下来就是扩展Application得到需求所描述的模型了,其中以下几个需求完全是基于上述模型可以直接扩展:
- 有的应用需要把代码托管到平台处
- 有的应用还需要数据库应用
- 有的应用不需要审核只需要用户授权即可直接添加到用户的列表中
最终得到以下类图