断断续续的做了一个月(主要是懒)
完成了
Server负责接受并返回Client的公网IP
Client负责定时轮询Server并在IP更新至阿里的DNS服务器
在client和Sever,go build main.go
client的启动参数分别为 accessKey accessId severAccessKey severIP:port
server启动参数为
severAccessKey
下一步将domain和RR放在配置文件中
第一版:
package com.michaelssss;
import java.util.ArrayList;
import java.util.List;
/**
* @author michaelssss
* @since 2017/12/7
*/
public class SimpleMap<T, P> {
private List<Pair<T, P>>[] buckets;
public SimpleMap() {
buckets = new ArrayList[64];
}
public void put(T key, P value) {
int hashCode = key.hashCode();
if (buckets[(hashCode % 64)] == null || buckets[(hashCode % 64)].isEmpty()) {
buckets[(hashCode % 64)] = new ArrayList<>();
buckets[(hashCode % 64)].add(new Pair<>(key, value));
} else {
boolean found = false;
for (Pair<T, P> pair : buckets[(hashCode % 64)]) {
if (pair.key.equals(key)) {
pair.value = value;
found = true;
}
}
if (!found) {
buckets[(hashCode % 64)].add(new Pair<>(key, value));
}
}
}
public P get(T t) {
P value = null;
int hashCode = t.hashCode();
if (null == buckets[(hashCode % 64)] || buckets[(hashCode % 64)].isEmpty()) {
return null;
} else {
for (Pair<T, P> pair : buckets[(hashCode % 64)]) {
if (pair.key.equals(t)) {
value = pair.value;
break;
}
}
}
return value;
}
private static class Pair<T, P> {
T key;
P value;
Pair(T key, P value) {
this.key = key;
this.value = value;
}
}
}
第二版(加入resize操作):
package com.michaelssss;
import java.util.ArrayList;
import java.util.List;
/**
* @author michaelssss
* @since 2017/12/7
*/
public class SimpleMap<T, P> {
private List<Pair<T, P>>[] buckets;
private float loadfactory = 0.75f;
private int bucketSize;
private int count;
public SimpleMap() {
bucketSize = 64;
buckets = new ArrayList[64];
}
public SimpleMap(int initSize) {
bucketSize = initSize;
buckets = new ArrayList[initSize];
}
public SimpleMap(int initSize, float loadfactory) {
this(initSize);
this.loadfactory = loadfactory;
}
public void put(T key, P value) {
int hashCode = key.hashCode();
if (buckets[(hashCode % bucketSize)] == null || buckets[(hashCode % bucketSize)].isEmpty()) {
buckets[(hashCode % bucketSize)] = new ArrayList<>();
buckets[(hashCode % bucketSize)].add(new Pair<>(key, value));
count++;
} else {
boolean found = false;
for (Pair<T, P> pair : buckets[(hashCode % bucketSize)]) {
if (pair.key.equals(key)) {
pair.value = value;
found = true;
}
}
if (!found) {
buckets[(hashCode % bucketSize)].add(new Pair<>(key, value));
count++;
}
}
if (loadfactory * count > bucketSize) {
resize();
}
}
private void resize() {
int newBucketSeize = bucketSize * 2;
List<Pair<T, P>>[] buckets = new ArrayList[newBucketSeize];
for (List<Pair<T, P>> bucket : this.buckets) {
if (null != bucket) {
for (Pair<T, P> pair : bucket) {
int hashCode = pair.key.hashCode();
if (null == buckets[hashCode % newBucketSeize]) {
buckets[hashCode % newBucketSeize] = new ArrayList<>();
}
buckets[hashCode % newBucketSeize].add(pair);
}
}
}
this.buckets = buckets;
this.bucketSize = newBucketSeize;
}
public P get(T t) {
P value = null;
int hashCode = t.hashCode();
if (null == buckets[(hashCode % bucketSize)] || buckets[(hashCode % bucketSize)].isEmpty()) {
return null;
} else {
for (Pair<T, P> pair : buckets[(hashCode % bucketSize)]) {
if (pair.key.equals(t)) {
value = pair.value;
break;
}
}
}
return value;
}
private final static class Pair<T, P> {
T key;
P value;
Pair(T key, P value) {
this.key = key;
this.value = value;
}
}
}
1.无论何种方式部署,一定要设置delay=-1
2.dubbo调用的序列化有可能不是同步的,即当你远程获取一些信息时候,如果反序列化时间较长,你读取对象信息的时候会直接报空指针异常
3.dubbo是网络连接,无论如何都应该降低调用次数,设计接口的时候最好是batchget或者是做Client部分做Proxy缓存
4.最好将Dubbo的重试机制干掉。。。快速失败,并在Client处做记录,已经遇到过因为Dubbo接口响应慢,多次重试导致直接Provider打爆
先来展示一段我司日常常见代码:
……………………
Abc = redisTemplate.opsValues().get(“******”);
if(null==Abc){
abc=………………一堆逻辑
redisTemplate.opsValues().set(“******”,Abc);
}
Return Abc;
从逻辑上来说这段代码并没有错误
但这样最终导致的结果是把所有外部的压力都转移到了redis上来了,极有可能导致把redis打爆,从而击穿数据库导致整个系统崩溃
另一种情况是,redis当共享内存用:
比如我们的zuul部件,每次都把用户的请求完整的set进redis,然后当下一个同session的转发进来后去redis去get,具体表现是redis看到日志是每当一个请求进来会出发两位数到三位数的redis请求(流量极端放大),尽管是zuul部件本身做到了无状态,但其实是用了redis做了共享状态。
这样依旧是把所有压力都放在了redis上面。引发问题更糟糕的是,我们的session内容存了太大的对象redis的并发能力遭到了限制,在少量用户下就已经会引发内部系统的崩溃。
正确的姿势是redis类似与一个单机系统里面不同进程的buffer/channel,在考虑上网络IO的重量级后,我们应该尽可能减少进程之间的通信,在这里的语境下应该是减少集群内之间的通信,从而避免把buffer/channel本身给弄挂了。
在第一种用法下,其实应该是将Abc的状态保存在redis但是Abc本身应该要存在当前结点上,这样就改变了集群内部通过redis传递对象,转而是传递信息了,比如我用时间作为Abc的特征,那么集群内部只需要传递特征时间就能够保持集群内部操作的幂等性,从原有的可能几kb的通讯变为几bit的通讯
第二种用法下,优化的手段就要更多了,首先第一点是减少session保存的数据,将不同业务之间的session分割开来减少session的大小。接着将请求按照一致性hash原理,同一个请求只从zuul集群的同一台服务器走,将保存的信息转换成本地内存,或者将用户-》集群的映射关系存入redis从而减少redis的使用量。
整个系统分为三个部分:
原始数据
包装成商品后数据
客户持有列表数据
原有设计是每一次客户获取客户持有列表数据都会从包装成商品之后的数据获取数据(包装成商品之后原有的原始数据的属性会有可能被商城变更)
因为Dubbo的方便性让人不自觉的就忽略掉了远程调用的IO是很重的
原有设计时,每个客户第一次访问会从原始数据+包装后商品数据进行遍历,然后存入redis,接着以后调用直接走redis。
当天上线后,发现原始数据的系统直接出现了百万次调用且因为代码笔误全部打到了数据库上,灰度环境紧急回滚
事后分析可能有以下几个原因:
1、不知道因何系统无法从redis上读取数据,都直接开始了调用
2、因为原有的设计可能流量只会放大N倍,但因为配合其他系统上线,增加了两段逻辑,流量放大为3N倍
3、因为dubbo的超时重试机制,流量再次放大三倍,直接导致整个系统的崩溃
优化方案:
将远程调用转为本地调用
1、给dubbo接口增加Proxy,作为本地缓存
2、定期从原始数据平台拉去数据,保证数据的一致性
3、其他逻辑保持不变
这样将网络请求变为本地内存调用,比较好的解决了因系统流量放大导致的系统雪崩情况
技术栈的选型:
第一点指的是在市场上找一个熟悉当前技术栈的人是否困难, 一般情况下开源软件的人员比较容易找, 但也仅限于初级人员, 若是需要到较深层次的改写或者应用, 无论任何技术栈都非常困难(多数情况下情景退化成自研)
第二点是用起来这个组件好不好用,简不简单,比如EJB这种在绑定WebSphere战车上,用起来非常舒服.或者你整体都是Spring,沿用了Spring技术套件也会很舒服
第三点指当前选型与原有选型发生冲突要进行改造改动的返回 ,当然如果一个项目真心是完全敏捷开发这个完全不需要考虑.大部分情况下,比如从Dubbo切换至SpringCloud,从SOAP到Probuf(比如当前我司….),冲突厉害了还要做技术演进方案…如果无法演进就更痛苦成本就变高
私货:
个人偏好充血模型,但是以Spring开发的WEB应用都是贫血模型, 所以技术栈还可能影响开发习惯和偏好
1.避免锁
1.1 预分配,外部不允许修改内部状态等
2.避免IO
3.异步化
4.数据落地尽可能批量化
另外,从应用建模时候尽可能让数据维护本身自己,而非外部系统修改(可以天然的并行化,而不需要考虑锁),具体来说DDD,ACTOR等等都是这种思想.
在一个理想状态下,不考虑跨语言的情况下,每个对象只能由自身维护其数据的情况下,那么扩展性能够达到最大,因为完全避免的锁
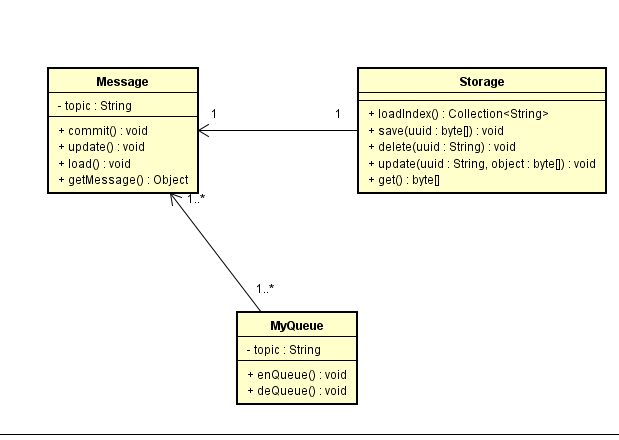
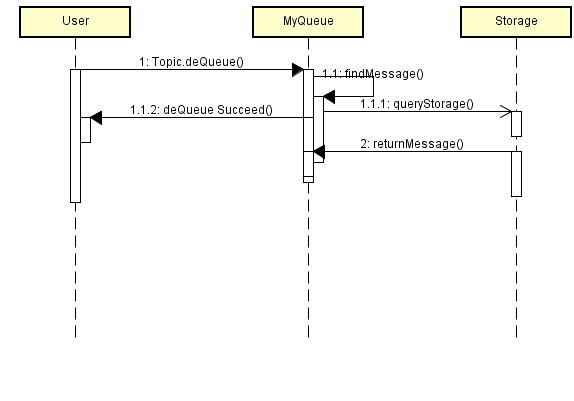
消息入队:

消息出队:
完全依赖Storage作为拓展点,若是单机消息队列,则直接实现单机Storage
若是集群存储则实现集群Storage
若是分布式存储则实现分布式的Storage
所有上层操作依赖Storage接口
分别是CompressFileStorage, SplitFileStorage
分别实现场景是,单消息单文件存储
多消息单文件存储
Github地址:
https://github.com/michaelssss/MyQueue
1.确定领域界限(通常由领域专家和架构师共同确定)
2.抽象领域的套路,就是通过和领域专家交流,确定出在当前领域下的各种套路
Example:
以软件发布作为一个领域来陈述:
首先确定,当前业务界限(已开发完毕,通过测试,需要在某个商城或者平台上架)
接下来,涉及,当前商店的适配(Adapter),提交审核(Commit,Audit),最后是上架(sell granted/publish)
以上作为最基本的讨论术语。而这些专业名词,也就是俗称的套路。
3.通过动态验证模型是否满足需求,否则转2。
不断的重复交流并验证,最终得出一个模型。(类似于软件开发中的迭代,这里是模型的迭代,而非软件的迭代,但模型的迭代能够深层次的影响软件的迭代)
只要模型抽象的足够好,面向对象中的SOLID原则会自然而然的呈现,而非刻意而为。
从一个比赛题目来看业务设计应该如何设计
先说,数据库设计如下
![D:\msg\602254985\Image\Group\Image2\D]6[ZU2KJ27UP8WFNDFZR8L.png](https://michaelssss.com/wp-content/uploads/2017/08/d-msg-602254985-image-group-image2-d6zu2kj27up8-1-1.png)
题目:
要求设计一个接口getBlogList(userid,int begin,int offset)
返回blog以下数据
{
“Blog”:[
“blogid”:xxx, //博客id
“createtime”:xxx, //博客创建时间,需最新的在最前羰
“readflag”:1/0, //当前用户的已读状态
“praiselist”:[“xxx”,”yyyy”,”zzz”,……], //当前博客的点赞人例表
“commentlist”:[“xxx”,”yyy”,”zzz”,……] //当前博客的评论人例表
]
“Blog”:[
“blogid”:xxx,
“createtime”:xxx,
“readflag”:1/0,
“praiselist”:[“xxx”,”yyyy”,”zzz”,……],
“commentlist”:[“xxx”,”yyy”,”zzz”,……]
]
……
}
模拟数据数量级为百万级别
让我们来看看再不考虑内存占用下的最优解:
所有表预存至本地内存
提前对所有数据做好计算,到时候单纯的根据bloguid就可以在N(1)的时间下拿到数据和对象
十条数据
耗时1ms
输出压缩json大小23KB

两百条数据
耗时16ms
输出压缩json大小485KB

接下来把点赞详情和阅读详情操作给去除
十条数据:
耗时低于ms级别
输出json压缩大小低于kb级别

两百条数据:
耗时2ms
输出压缩json大小11KB

接下来把点赞数和阅读数加入操作中
十条数据:
耗时1ms
输出压缩json大小低于KB数量级

两百条数据
耗时10ms
输出压缩json大小17KB

问题在于,现实系统中,博文数量及点赞数一般的比这些模拟数据要大得多,且不可能完全load进内存中.
在上面的最优解中,瓶颈在于输出的数据量,也就是网络IO瓶颈
单次map是内存操作,一般是ns级别
网络通信的的时间一般是ms级别
彼此相差三个数量级,那么可以猜想,无论如何优化系统的响应时间也应该与这次测试相差三个数量级甚至更多.
那么以上题目放在实际系统场景中问题是什么呢?
针对以上,从业务上应该做如下规避: