效率优先
开场白真难,好,开场结束
什么是低效实践
我是以java语言为主力开发语言的代码编写人员,同时还负责我们所有的服务器的部署及维护, 实践中遇到最痛苦的事情莫过于, 精细化管理一切代码行为
为什么MyBatis在我的项目中很糟糕
我们团队一共就五个人,两个做后端,一个前端,一个原型设计,外加一个对外沟通的部门负责人.在一开始的选型中, 选中的框架是使用mybatis+springboot+vue来完成功能,我们主要是采集工厂生产过程中关键点温度的变化,以及保温性能的数据。
对于工业化设备监控来说,开发过程中最大的问题是,我们的模型的字段会在开发过程中不断的更新,于是我们实践中就会将mybatis当成一个Orm框架来使用,基本来说,就是只是用CRUD,每个对象是一张表,操作顺序都是查出对象-》修改对象-》回写数据库,这种半自动的工具在这样的实践中就会带来需要管理的代码实在太多,而且基本为样板代码,更严重的是,对象直接的关系维护必须手工写代码(这种代码基本就是样板代码,其实Hibernate这种框架都已经解决好了),对于一个小团队来说这是一个不可取的行为。没那么多精力,也不应该花那么多精力来维护这些样板代码。
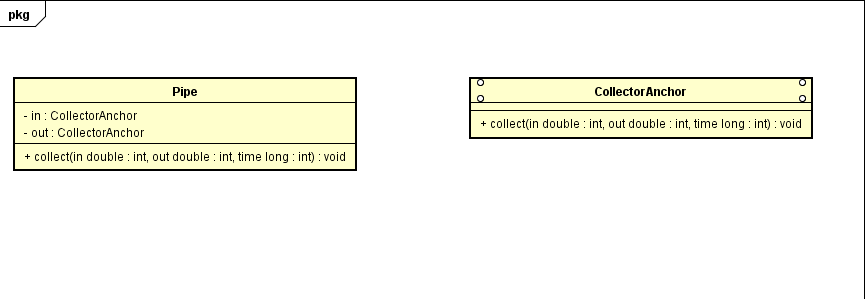
举个栗子
我们对于采集点管理进行建模,首先有区域,然后有管道,接着有测温点信息,最后测温点有测温点数据
然后我们需要维护区域与管道之间的关系,管道与测温点之间的关系,区域与区域之间的关系,测温点数据与测温点之间的关系
一顿操作,需要有四个Dao,对应四个Entity,然后关系(就是Repository的职责)有四个Repository。
以上全是样板代码
提升效率
问题的关键在于如何将我们的开发人员从无趣且繁琐的样板代码实施中解放出来呢,答案在EJB中已经被实践,就是全自动的ORM框架
全自动的ORM带来的是开发人员不用再去做大量重复性工作以维护数据之间的关系和正确性
对于一个我们进行中的项目,采用MyBatis plus方案需要实现四个Dao,四个Repository,还有实现四个Entity,而改用Jpa/Hibernate之后,代码数量减少到四个Repository,无需实现Entity,Dao,而且SpringDataJpa已经可以通过动态代理方式生成代码,Repository是无需实现,只需要声明接口
原先使用了接近5(人/日)的工作量才完成的方案,改用Jpa后只需要0.5(人/日)
需要回避的点
全自动ORM是否有缺陷?
有,一是对象与数据库之间的关系需要靠一套不可变的规则维持,但是代码总是有人维护的,而且Hibernate的实现人并不是我们,若规则变动,我们的数据全部报废
二是全自动的ORM会有解析对象的性能开销,具体到我们项目是,启动时间增加两秒到五秒
三是需要实现一层控制事务的Service
解决方法也很简单,版本别动,启动时间其实无所谓,然后多采用懒加载,事务无非就是多一个Transactional的注解
结语
- mybatis不适用于人少的项目,开发人员少的情况下,要优先考虑开发效率
- 绝大部分开发人员真的不需要考虑从持久化方案中榨取更多性能,而榨取的通道多数会变成你的维护成本
- 性能有绝对要求下应该考虑其他方案而不采用数据库
- 真心建议国内的风气变一下,我在调研中发现mybatis最后演化出了mybatisplus的方案,一个四不像的方案,既没有减轻开发人员维护数据库的负担,也没有减少样板代码(mybatisplus依旧要手工维护关系)