从一个比赛题目来看业务设计应该如何设计
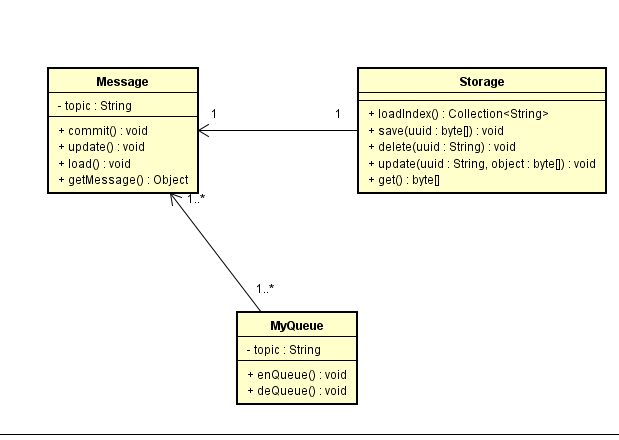
先说,数据库设计如下
![D:\msg\602254985\Image\Group\Image2\D]6[ZU2KJ27UP8WFNDFZR8L.png](https://michaelssss.com/wp-content/uploads/2017/08/d-msg-602254985-image-group-image2-d6zu2kj27up8-1-1.png)
题目:
要求设计一个接口getBlogList(userid,int begin,int offset)
返回blog以下数据
{
“Blog”:[
“blogid”:xxx, //博客id
“createtime”:xxx, //博客创建时间,需最新的在最前羰
“readflag”:1/0, //当前用户的已读状态
“praiselist”:[“xxx”,”yyyy”,”zzz”,……], //当前博客的点赞人例表
“commentlist”:[“xxx”,”yyy”,”zzz”,……] //当前博客的评论人例表
]
“Blog”:[
“blogid”:xxx,
“createtime”:xxx,
“readflag”:1/0,
“praiselist”:[“xxx”,”yyyy”,”zzz”,……],
“commentlist”:[“xxx”,”yyy”,”zzz”,……]
]
……
}
模拟数据数量级为百万级别
让我们来看看再不考虑内存占用下的最优解:
所有表预存至本地内存
提前对所有数据做好计算,到时候单纯的根据bloguid就可以在N(1)的时间下拿到数据和对象
十条数据
耗时1ms
输出压缩json大小23KB

两百条数据
耗时16ms
输出压缩json大小485KB

接下来把点赞详情和阅读详情操作给去除
十条数据:
耗时低于ms级别
输出json压缩大小低于kb级别

两百条数据:
耗时2ms
输出压缩json大小11KB

接下来把点赞数和阅读数加入操作中
十条数据:
耗时1ms
输出压缩json大小低于KB数量级

两百条数据
耗时10ms
输出压缩json大小17KB

问题在于,现实系统中,博文数量及点赞数一般的比这些模拟数据要大得多,且不可能完全load进内存中.
在上面的最优解中,瓶颈在于输出的数据量,也就是网络IO瓶颈
单次map是内存操作,一般是ns级别
网络通信的的时间一般是ms级别
彼此相差三个数量级,那么可以猜想,无论如何优化系统的响应时间也应该与这次测试相差三个数量级甚至更多.
那么以上题目放在实际系统场景中问题是什么呢?
- 每次请求时候才去做数据的计算统计排序(因为不允许preload就不允许启动的时候计算完毕并启用)
- 单次请求的数据没有区分重点和无关紧要点(你看个列表为啥要详情),导致单次查询数据量爆炸,不仅是查询的量过多,而且输出的量也是继续攀升,导致网络IO负担明显
针对以上,从业务上应该做如下规避:
- 输出列表时候不应该把点赞和评论的详情带上,而应该只需要统计量,减少输出结果的
- 单独维护一个列表,用于排序条件,比较使用<K.V>系统避免在业务代码中动态的进行计算(减少每次请求的遍历时间);
- 如点赞数和评论数也可以维护在<K.V>系统内,数据库只是一个序列化的仓库
- 只有用户需要查看点赞详情和评论详情的时候才去请求查询