1.避免锁
1.1 预分配,外部不允许修改内部状态等
2.避免IO
3.异步化
4.数据落地尽可能批量化
另外,从应用建模时候尽可能让数据维护本身自己,而非外部系统修改(可以天然的并行化,而不需要考虑锁),具体来说DDD,ACTOR等等都是这种思想.
在一个理想状态下,不考虑跨语言的情况下,每个对象只能由自身维护其数据的情况下,那么扩展性能够达到最大,因为完全避免的锁
1.避免锁
1.1 预分配,外部不允许修改内部状态等
2.避免IO
3.异步化
4.数据落地尽可能批量化
另外,从应用建模时候尽可能让数据维护本身自己,而非外部系统修改(可以天然的并行化,而不需要考虑锁),具体来说DDD,ACTOR等等都是这种思想.
在一个理想状态下,不考虑跨语言的情况下,每个对象只能由自身维护其数据的情况下,那么扩展性能够达到最大,因为完全避免的锁
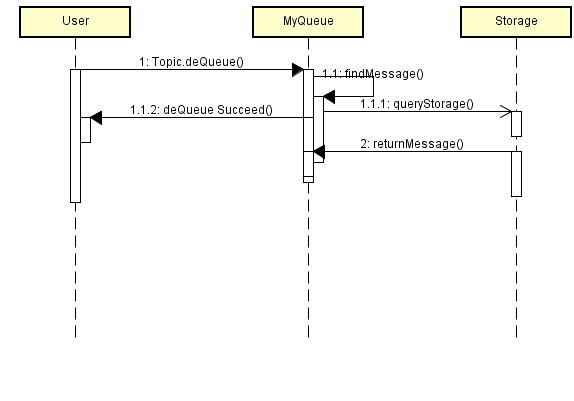
消息入队:

消息出队:
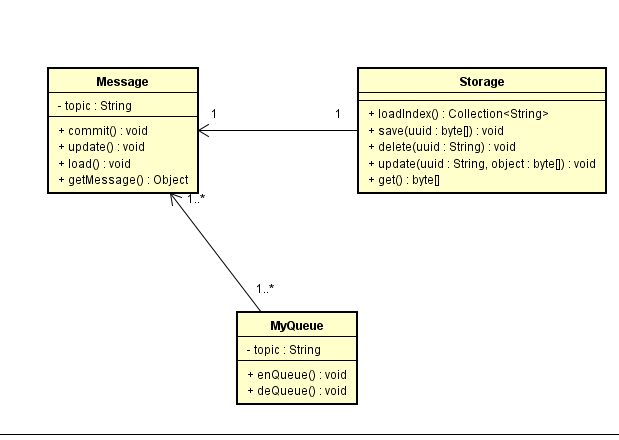
完全依赖Storage作为拓展点,若是单机消息队列,则直接实现单机Storage
若是集群存储则实现集群Storage
若是分布式存储则实现分布式的Storage
所有上层操作依赖Storage接口
分别是CompressFileStorage, SplitFileStorage
分别实现场景是,单消息单文件存储
多消息单文件存储
Github地址:
https://github.com/michaelssss/MyQueue
1.确定领域界限(通常由领域专家和架构师共同确定)
2.抽象领域的套路,就是通过和领域专家交流,确定出在当前领域下的各种套路
Example:
以软件发布作为一个领域来陈述:
首先确定,当前业务界限(已开发完毕,通过测试,需要在某个商城或者平台上架)
接下来,涉及,当前商店的适配(Adapter),提交审核(Commit,Audit),最后是上架(sell granted/publish)
以上作为最基本的讨论术语。而这些专业名词,也就是俗称的套路。
3.通过动态验证模型是否满足需求,否则转2。
不断的重复交流并验证,最终得出一个模型。(类似于软件开发中的迭代,这里是模型的迭代,而非软件的迭代,但模型的迭代能够深层次的影响软件的迭代)
只要模型抽象的足够好,面向对象中的SOLID原则会自然而然的呈现,而非刻意而为。